两种策略
生成式学习
生成有结构的复杂物件,例如文句、影像、语音等。
这些物件通常是由小的物件构成的
文句是由 token 所构成。
token:
在中文指「字」;
在英文指 word piece, unbreakable -> un break able
原因: 英文单词穷举不了,而 word piece 是可以穷举的
影像由像素构成
例如,16k 取樣頻率, 每秒有 16,000 個取樣點
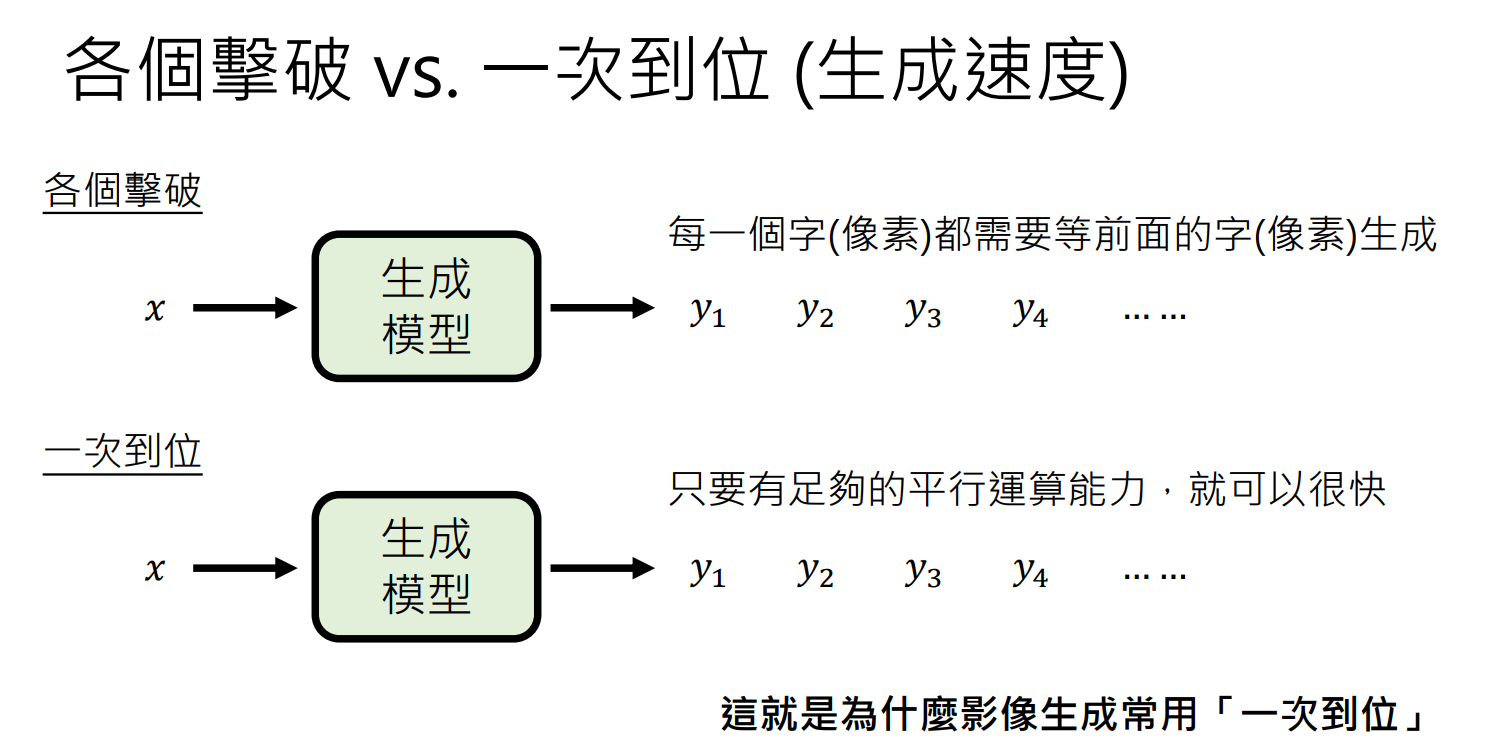
策略1-各个击破
输入:
`机器学习是什么?`输出:逐个生成
`机``器``学``习`...`[END]`
逐个生成像素点,最后形成整张图
专业术语是:Autoregressive (AR) model
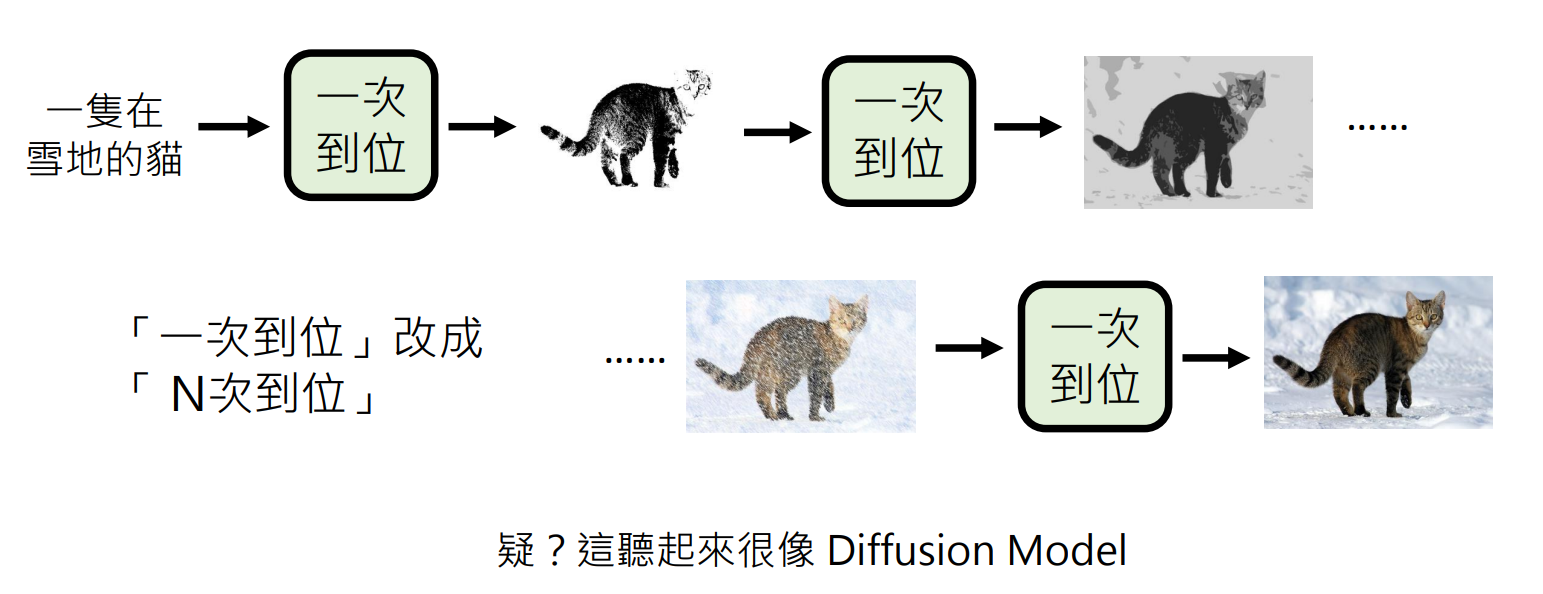
策略2-一次到位
专业术语是:Non-autoregressive (NAR) model
一次生成文本,但如何确定生成长度?有下面几个可能:
永远输出固定长度,假如里面有 [END],则将后面丢弃掉。从使用者的角度看,每次长度是不一样的。
先生成输出长度,再生成文本
策略比较
「各个击破」生成的品质较好,「一次到位」生成的品质较差。
当问及`李宏毅的职业是什么?`,可以回答 `演员` 或者 `老师` (两人同名)。
如果采用「各个击破」,一开始 `老`和`演`的几率差不多。假如生成 `老` 字,则下一个字是 `师`的几率就比 `员` 高很多。
如果采用「 一次到位」,第一个字是`老`和`演`的几率差不多,第二个字是 `师`和`员`的几率差不多,可能会导致生成 `老员` 这种奇怪的语句。
各個擊破 (Autoregressive, AR) | 一次到位 (Non-autoregressive, NAR) | |
|---|---|---|
速度 | 胜 | |
品质 | 胜 | |
应用 | 常用于文字 | 常用于影像 |
有沒有可能兩種策略截長補短?
两者结合
即各个击破+一次到位:
语音合成: 先用「各个击破」产生一个中间产物(每秒 100 个向量;决定大方向),再用「一次到位」把中间产物变成 16k 的取样频率。
图像生成:
直接生成一张图片可能会比较模糊。