StableDiffusion
Framework
Text Encoder
输入:文字
输出:一个一个的向量
Generation Model(现在一般用 Diffusion Model)
输入:杂讯和文字的encoder
输出:“中间产物”,图片的压缩版本,可以是人看得懂的但比较小且模糊的图片,也可以是人看不懂的
Decoder
输入:上述的图片压缩版本
输出:图片
这个部分一般是分开训练,然后组合起来的。
Stable Diffusion
DALL-E series
Imagen
TextEncoder
可以用 ChatGPT 或 Bert 作为 Text Encoder
最开始的文字对最后生成图片影响很大。 相较之下,Diffusion Model 对结果的影响不是很大。
Fréchet Inception Distance (FID)
如何衡量一张图片的好坏,如何评估文生图模型的好坏?
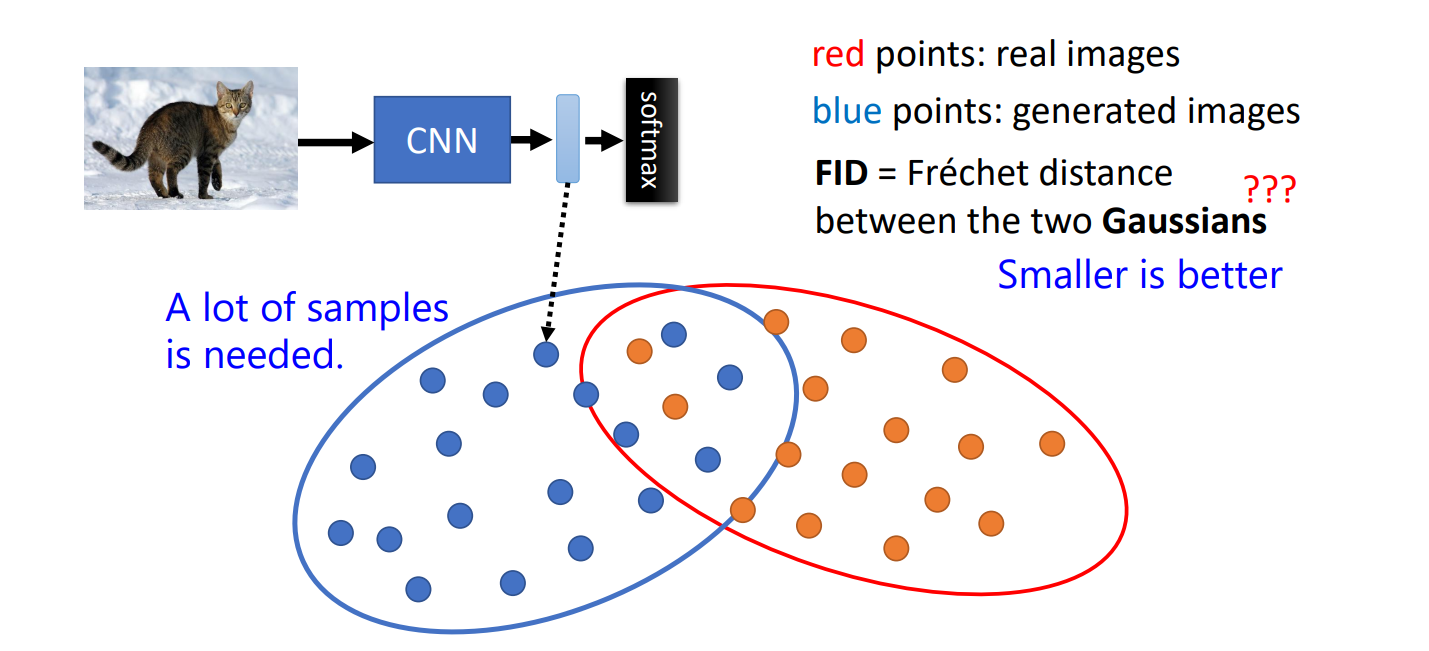
https://arxiv.org/abs/1706.08500
Contrastive Language-Image Pre-Training
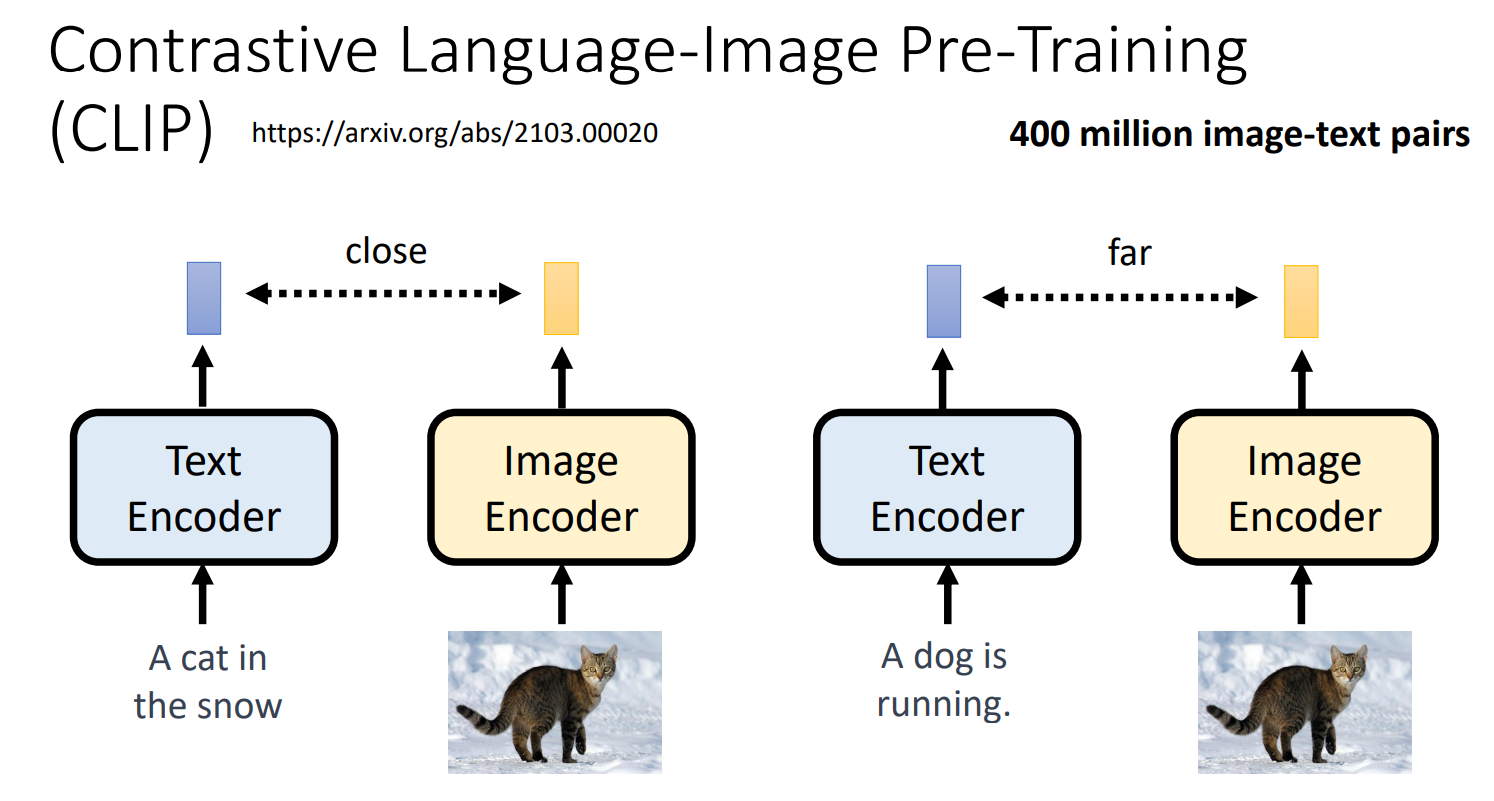
https://arxiv.org/abs/2103.00020
Decoder
Decoder can be trained without labelled data.
没有跟影像成对的资料比有成对的资料更多。Decoder 的训练有一个优势,那就是不需要用成对的资料来训练。
「中間產物」為小圖
假如中间产物是小图,可以训练一个输入是小图,输出是大图的 Decoder。 这样,仅需要把原有的图片变成小图,就有训练资料了。
「中間產物」為「Latent Representation」
训练一个 Auto-encoder,输入是图片,输出是 Latent Representation,然后将该输出作为要训练的 decoder 的输入,期待其输出接近最开始输入的图片。 (可以把这个中间产物理解为人类看不懂的小图)
Generation Model
不好描述,看课程