训练GPT
G: Generative 生成 P: **Pre-trained** 预训练 T: Transformer
一般机器学习
收集大量中英成对例句:
输入 | 输出 |
|---|---|
I eat an apple | 我吃苹果 |
You eat an orange | 你吃橘子 |
然后让机器从这些例子中寻找函式 $f$,这个 $f$ 可能会包括如下规则:
输入 | 输出 |
|---|---|
I | 我 |
you | 你 |
apple | 苹果 |
orange | 橘子 |
当给机器 "You eat an apple" 时,期待机器能正确翻译出 "你吃苹果"。
这是一般的机器学习方式(督导式学习)。
假如将上述的机器学习方式套用到 ChatGPT 上,则需要**大量**如下成对的例子:
输入 | 输出 |
|---|---|
台灣第一高峰是那一座? | 玉山 |
幫我修改這段文字 …… | 好的 …… |
教我做壞事 …… | 這是不對的 |
然后让机器寻找函式 $f$ 。
但是这样训练出的能力可能非常有限,因为人能提供的成对例子是有限的。比如说,提供的训练资料中没有 "世界第一高山是哪一座?",则 ChatGPT 不可能回答出 ”喜马拉雅山“
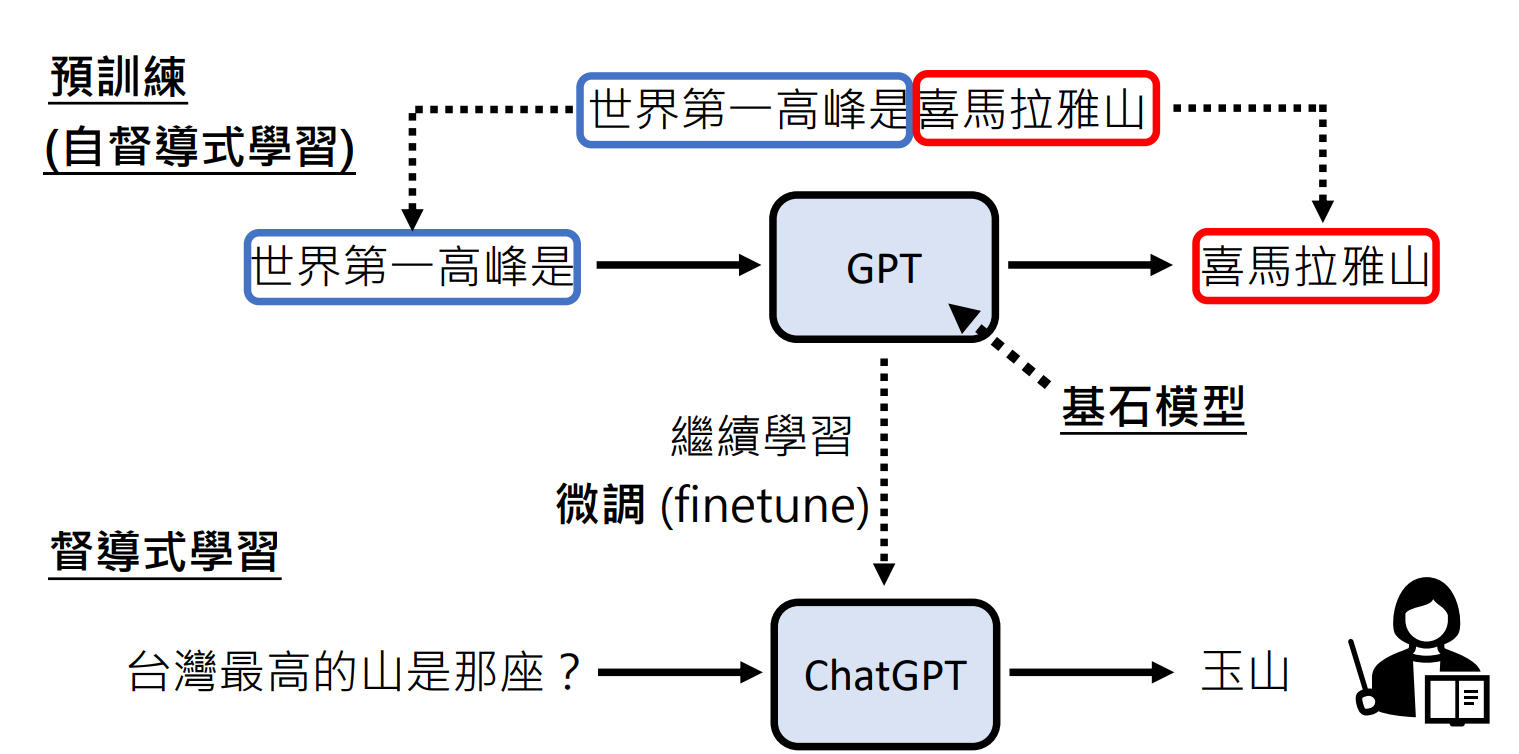
预训练
将网上的资料拆成成对资料。例如,”世界第一高峰是喜马拉雅山“,则将其拆成 输入是”世界第一高峰是“ 输出是 ”喜马拉雅山“ 的成对资料。 也就是说,网络上的每一个句子都可以用来教机器作文字接龙。
Model | 年份 | 训练资料 | 参数数量 |
|---|---|---|---|
GPT | 2018 | 1GB | 117M |
GPT-2 | 2019 | 40GB | 1542M |
GPT-3 | 2020 | 570GB | 175B |
GPT-2 已经有回答问题的能力,虽然很弱。
570GB 相当于 哈利波特全集 30万遍
GPT-3 原先在网络上爬到的资料有 45T,只选择了 570GB 的资料出来训练
GPT 只从网络资料学习可能会导致生成的答案不受人的提问控制。
例如,让 GPT 解释代码,GPT 可能会生成考题。

督导式学习
到 GPT3为止,GPT的训练不需要人类老师。但是从 GPT 到 ChatGPT 就需要人类老师。也就是说,ChatGPT 是 GPT系列经过督导式学习的结果。
ChatGPT 能回答出多种语言,(李宏毅老师认为)这很可能不需要靠翻译引擎,仅凭人类老师教的几种语言就可以自动学会其它语言。 其依据是: Multi-BERT 在104种语言上做过预训练,学习了英文阅读能力测验后,也能自动学会中文的阅读能力测验。类比来说,有一个人要考中文阅读能力测验,但做过的训练题都是英文的,然后祼考中文,居然也能答对,并且没有用到翻译。
增强式学习
(Reinforcement Learning, RL)
判断 ChatGPT 生成的答案是 好 还是 坏。
督导式学习 需要人提供正确的答案,较辛苦。 增强式学习 仅需点赞或点”倒“赞,较省力。
适用于人类自己也不知道答案的时候。
例如,让 ChatGPT ”请帮我写诗赞美AI“ ,我们人可能也想不出一个合理的回答。使用增强式学习时,不需要人来想,而是 AI 生成,我们给出 好 还是 坏 的反馈即可。