两种期待
介绍
GPT: 文字接龙 BERT: 文字填空
期待一:成為專才,解某一個特定任務。
例如翻译,输入是文本,输出是该文本的翻译
例如摘要,输入是文本,输出是该文本的摘要
期待二:成為通才(這就是今日 ChatGPT 走的路線)
想要翻译,输入是
`对以下文句做翻译`+ 所需翻译的文本想要摘要,输入是
`对以下文句做摘要`+ 所需摘要的文本
训练通才的想法以前就有了:
优点
成為專才的好處:專才在單一任務上有機會贏過通才
ChatGPT 在翻译任务上比不过专门的翻译模型。
Is ChatGPT A Good Translator? A Preliminary Study https://arxiv.org/abs/2301.08 How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation https://arxiv.org/abs/2302.09
成為通才的好處:只要重新設計 prompt 就可以快速開發新功能, 不用寫程式
指令是 `请对以下文句做摘要`,如果生成过长,直接修改指令为 `请给我100字以内的摘要`,不需要修程式
用法
专才用法
对预训练模型做改造,使其成为翻译专才、摘要专才等
加外掛(Head)详见 https://youtu.be/gh0hewYkjgo
微调(Finetune), Update network parameters by gradient descent
以翻译为例,将语言模型的参数当作训练的初始化参数(Initialization),用翻译的资料来微调模型里面的参数。
在大语言模型加一个额外的插件,不修改原模型,仅修改 Adapter 里面的参数
好处: 原先100个任务就要存100个大模型,使用 Adapter 的话只需存 1 个大模型和 100 个 adapter
通才用法
范例学习
In-context Learning
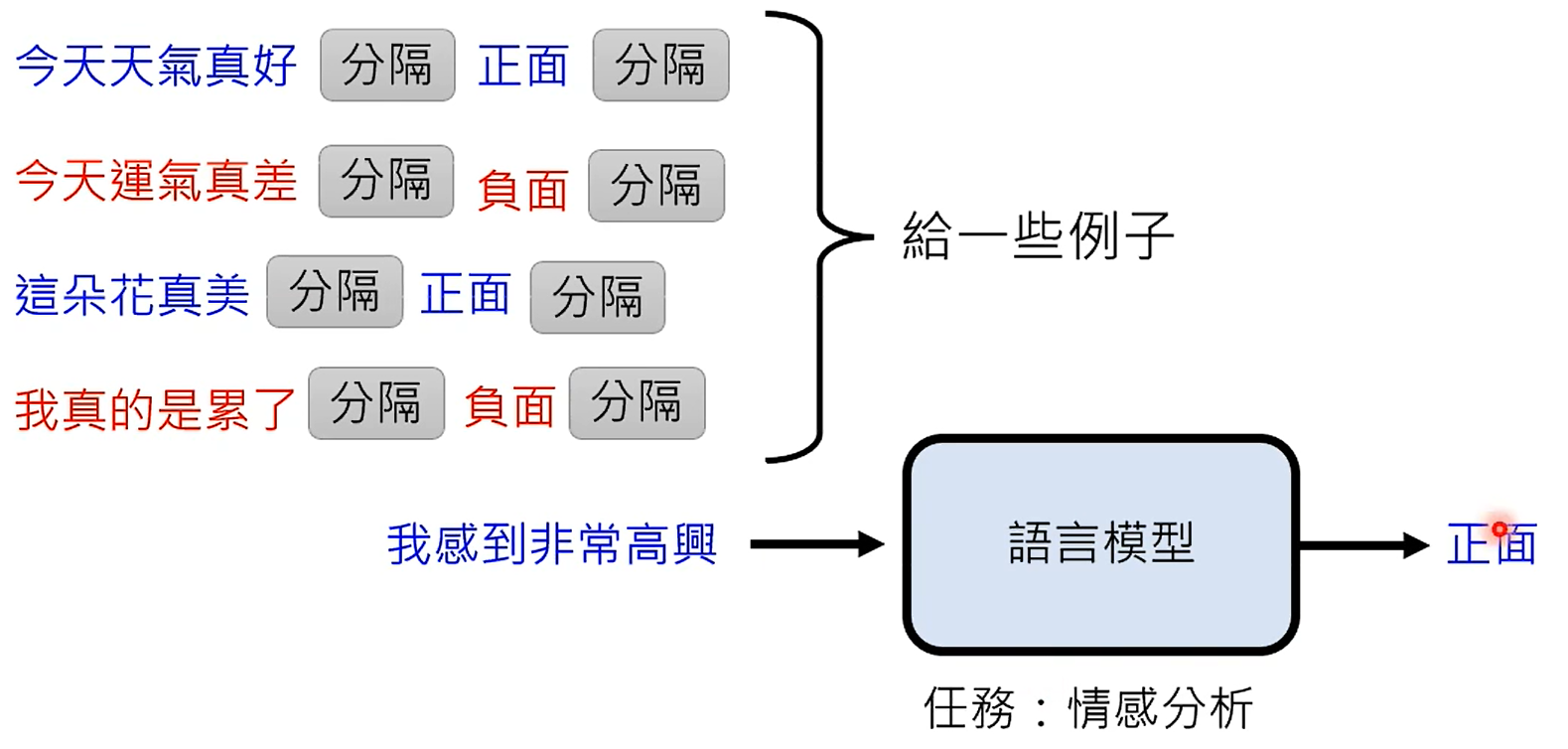
机器真的能像人一样,靠这些例子就能学习吗?
作对比:提供正确的例子 VS 提供错误的例子 VS 不提供例子
提供错误例子的做法是:故意给错误标注(`今天天气很好`对应`负面` 或 输入是完全无关的内容 `&#(&$%@#`)。
结果发现:提供正确的例子 略好过 提供较差的例子,没有提供例子的最差。
一个可能的原因是:这个模型本來就會做情感分析,只是需要被指出需要做情感任務。
另一个依据是,提供的例子数量不需要很多,提供4-8个例子后模型的正确率就开始收敛了,再增加例子数量正确率也不会有明显提升。
In-context Learning 也能做到 Learning。详情需要读下面论文:
模型越大,受错误例子的影响越大。因此,可能机器要从范例中学习,需要很大的模型。(甚至能直接学到「分类(Classification)」?)
上述例子机器并没有学习 In-context Learning,只有文字接龙,但却很神奇地有 In-context Learning 的能力。
让机器学习 In-context Learning的方法:

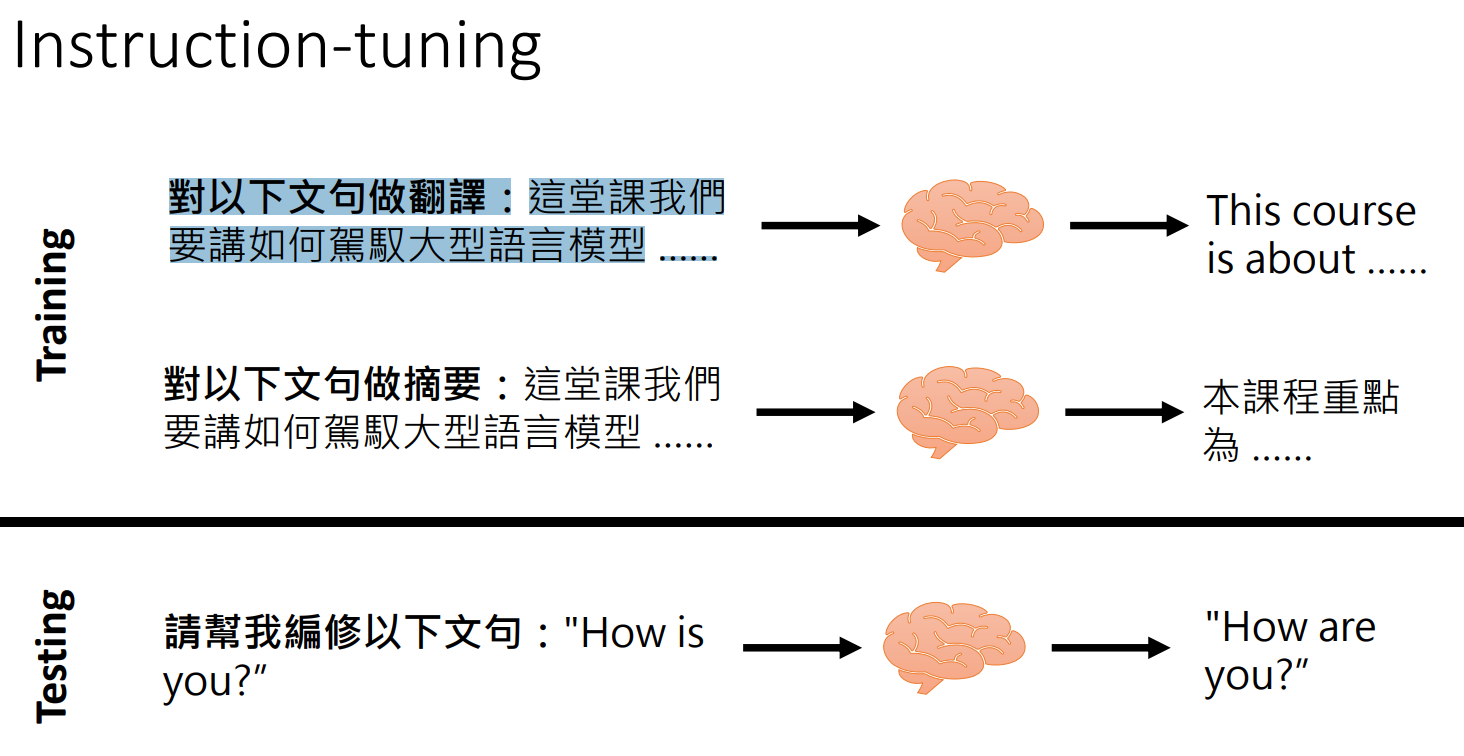
指令学习
直接给机器指令来执行任务(Instruction Learning),光有文字接龙后的模型并不够,还需要经过微调(Instruction-tuning)才能看懂人的指令。
微调方法:
思维链
Chain of Thought (CoT) Prompting
相比于直接让 AI 给出答案,让 AI 进行「分而治之」的效果会更好。
例如让 AI 分步做数学题
https://arxiv.org/abs/2201.11903
Chain of Thought (CoT) Prompting:
做法 | 效果 | |
|---|---|---|
Few-shot | 提供范例,输出直接是答案 | 差 |
Few-shot-Cot | 提供范例,输出是步骤加答案 | 好 |
Zero-shot | 不提供范例,输出直接是答案 | 差 |
Zero-shot-Cot | 不提供范例,加一句 | 好 |
注意,ChatGPT自动支持分而治之
学名:self-consistency
用来搭配 Chain of Thought
让机器做多次分而治之,产生多个推理过程+答案,比较各个答案,出现最多次的答案很有可能是正确答案
https://arxiv.org/abs/2203.11171
Least-to-Most Prompting
https://arxiv.org/abs/2205.10625
自动找指令
用機器來找 Prompt:
Hard Prompt ---> Soft Prompt
Using reinforcement learning
Using an LM to find prompt
自动找的 `Let's work this out in a step by step way to be sure we have the right answer.` 比人类想的 `Let's think step by step` 还要好。
https://sites.google.com/view/automatic-prompt-engineer
AACL 2022 Tutorial: Recent Advances in Pre-trained Language Models: Why Do They Work and How to Use Them Link: https://d223302.github.io/AACL2022-Pretrain-Language-ModelTutorial/