参数越多,训练资料越多,Loss越低。
https://arxiv.org/abs/2001.08361
大模型的顿悟时刻
学名是:Emergent Ability
模型的能力不是随着模型变大逐渐增强的,而是大到某个程度突然有了解决问题的能力。 https://arxiv.org/pdf/2206.07682.pdf
可能的原因是:
大小 | 能力 | 评分 |
|---|---|---|
小 | 什么都不会 | 0分 |
中 | 公式列对了,但计算错误 | 0分 |
大 | 公式列对了,计算也正确 | 100分 |
Chain of thought
Instruction tuning
Scratchpad https://arxiv.org/abs/2112.00114
Calibration https://arxiv.org/abs/2207.05221 語言模型知不知道自己不知道?
Language Models (Mostly) Know What They Know https://arxiv.org/abs/2207.05221 https://arxiv.org/pdf/2206.07682.pdf
一般正常的任务是模型越大效果越好,有没有一些任务是模型越大效果越差的呢?有一个比赛来征求这样的任务,并且有奖金: https://github.com/inverse-scaling/prize
有这样一种情况,小模型的效果比较好,比较大的模型效果比较差,但更大的模型又好起来了,呈 U 形图。因此上述比赛可能是因为模型还不够大。
U形图出现的可能原因是:一知半解吃大虧
https://arxiv.org/abs/2211.02011
模型还能不能更大?
Switch Transformer 有 1.6T 的参数 https://www.jmlr.org/papers/v23/21-0998.html
大资料的重要性
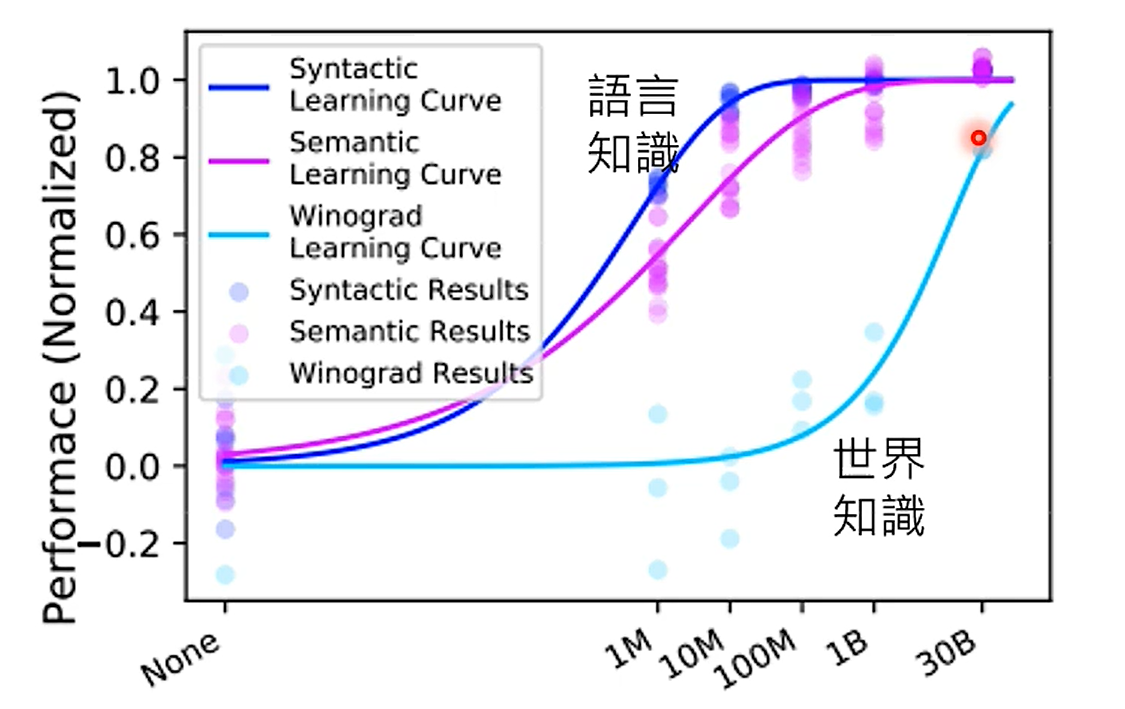 先解释图中两个知识:
先解释图中两个知识:
语言知识:用词、语法等。
世界知识:对世界、物理规则有正确的认识。举例来说,“我被冰块烫到手了”,符合语言知识,不符合世界知识。
对于语言知识,可能10M的资料足够了,但对于世界知识,我们需要更大量的资料。
Content Filtering 过滤有害内容
Text Extraction 去除 HTML tag(保留项目符号等)
Quallity FIltering 用规则去除「低品质」资料
Repetition Removal 去除重复资料
Document Deduplication 去除重复资料
Test-set Filtering 为了实验的严谨,训练集里不应该有测试集里的数据
https://arxiv.org/abs/2112.11446
去除重复资料的重要性: https://arxiv.org/abs/2107.06499
在同等算力资源下,是选择「小模型大资料」好,还是「大模型小资料」好?
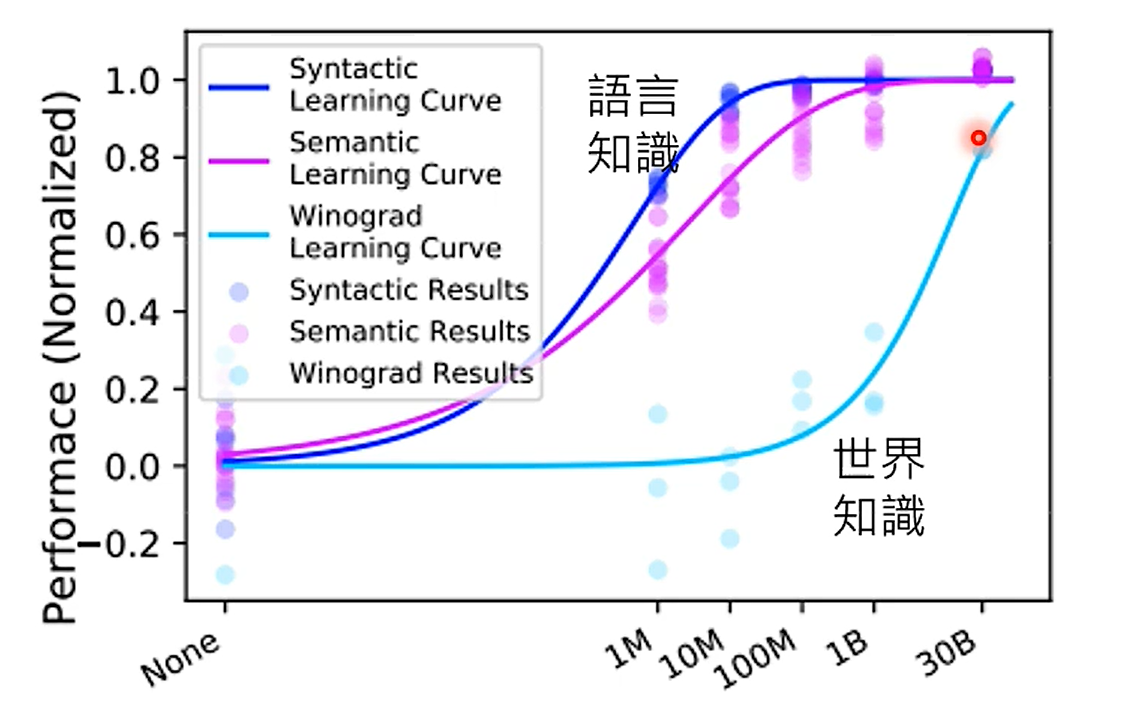 https://arxiv.org/abs/2203.15556
https://arxiv.org/abs/2203.15556
从该图上看,大家倾向于将算力投入在模型上,而不是训练资料上。这是否明智呢?
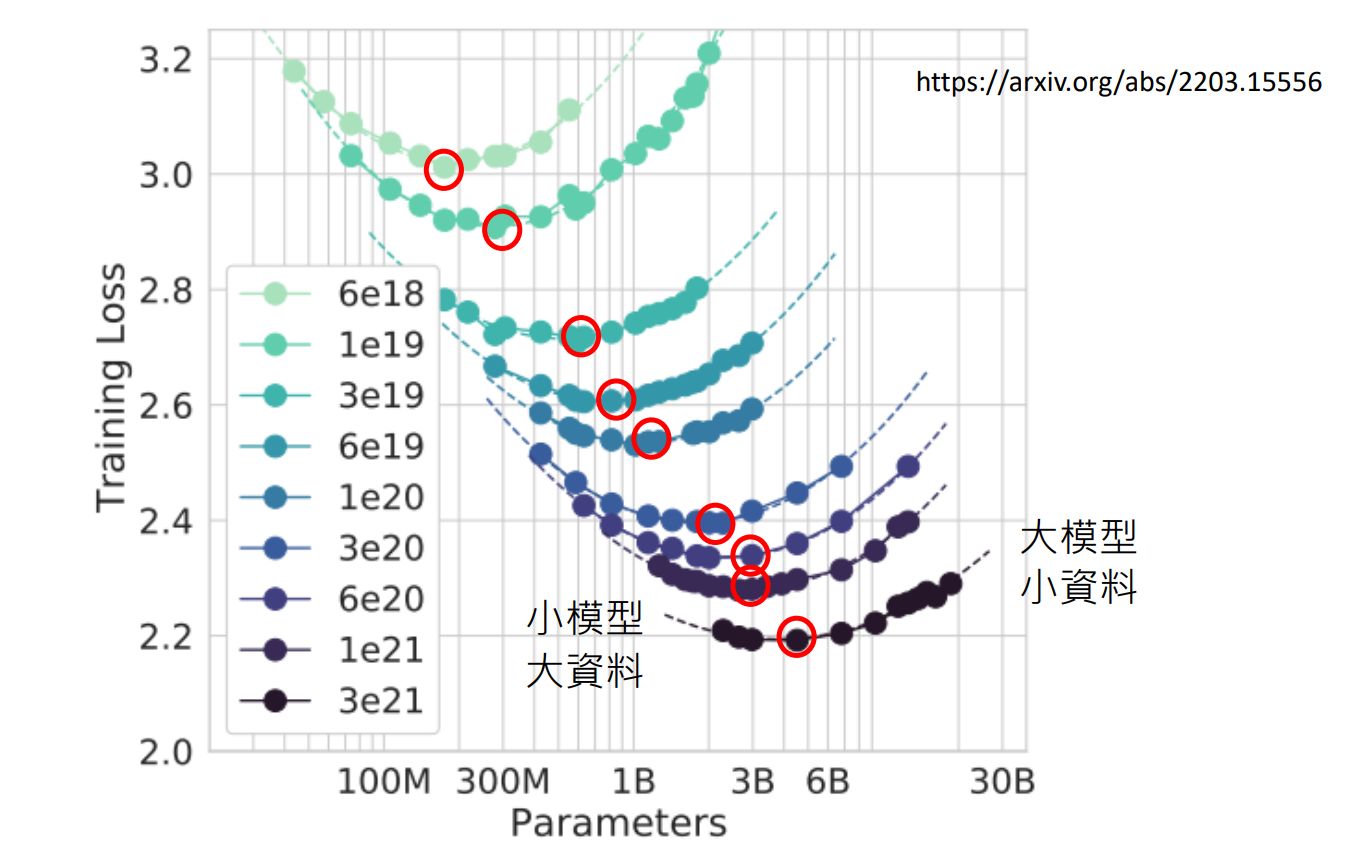 https://arxiv.org/abs/2203.15556
https://arxiv.org/abs/2203.15556
上面这张图,
虚线代表固定的运算资源,不同颜色代表不同运算资源
纵轴是文字接龙预测的程度,值越小意味着预测得越好
横轴是模型参数的量
也就是说,线的左侧表示「小模型大资料」,右侧表示「大模型小资料」
「小模型大资料」类比为「学而不思」,「大模型小资料」类比为「思而不学」
从实验结果是 U 形图 来看,「学」和「思」平衡时最好
将这些最低点连起来可以做到,从固定的运算资源推测其最好的参数量和训练资料量
实验对比:同样算力下,Chinchilla (小模型、大資料) vs. Gopher (大模型、小資料),Chinchilla胜
由此可见,过去觉得模型越大越好的做法可能并不正确。现在的模型也许足够大了,应该加大训练资料。例如现在的 MetaLM就是这样做的 https://arxiv.org/abs/2
Instruction-tuning
然而我们实际关心的并不是文字接龙的正确率,而是我们最终要解决的任务。在我们要解决的任务直接做 Instruction-tuning 是比较有效的。
https://arxiv.org/abs/2210.11416
ChatGPT https://openai.com/blog/chatgpt/
Instruct GPT https://arxiv.org/abs/2203.02155
即使是小模型,如果有人类老师的反馈,是有可能胜过没有做reinforce learing的大模型的。
这也是为什么 ChatGPT 更加成功,因为有无数人在用,OpenAI 非常清楚人们对语言模型真实的使用情况是什么样的。
另辟蹊径-KNNLM
完全看不懂