机器学习基本原理
类别
机器学习就是让机器自动找一个函式。
ChatGPT
输入: 一个句子
输出: 这个句子后面应该接哪个字。
Midjourney
输入: 一个句子
输出: 一张图片。
AlphaGo
输入: 棋盘上黑子和白子落子的位置
输出: 下一步落子的位置
根据函式的输出可以分成两类:
回归 (Regression)
分类 (Classification)
函式的输出是个数值
PM2.5预测器:
输入:今天的PM2.5,温度等等
输出:明天的PM2.5数值
函式的输出是个类别 (选择题)
邮件过滤器:
输入: 邮件
输出:是垃圾邮件,不是垃圾邮件
生成有結構的物件 (例如:影像、文句)
又叫做「生成式學習」 (Generative Learning)
ChatGPT 是哪一类机器学习呢?
ChatGPT 实际上做的事情是:输入是“任意字符”,输出是 “从任意字符中挑一个”。从这个角度讲,是分类。
使用者感受到的功能是:输入是“任意句子”,输出是“一个完整的回答”。从这个角度讲,是生产式学习,更具体而言,是把生成式学习拆解成多个分类问题。
三步骤简述
找出函式的三步骤:
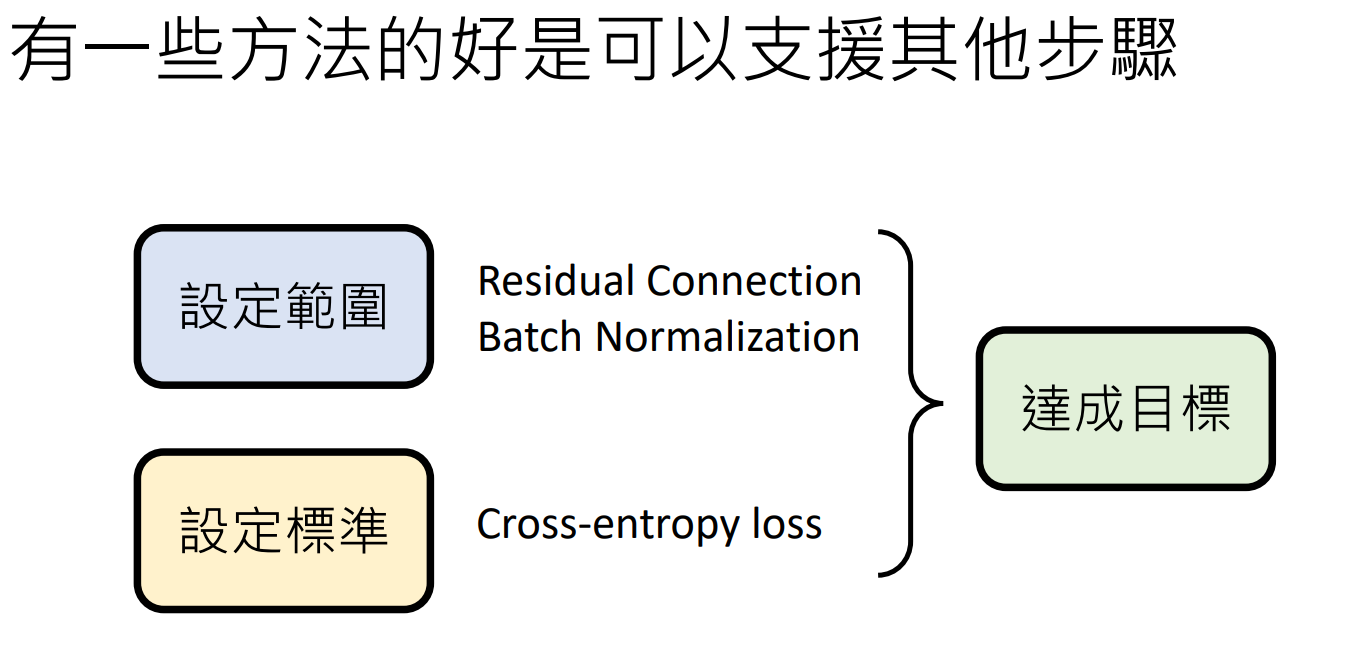
设定范围
设定标准
达成目标
但在此之前,要先决定要找什么样的函数,也就是先确定好目标,确定想要做的应用。这个问题虽然与技术无关,但却至关重要。
设定范围
确定出候选函式的集合 (Model)
深度學習中類神經網路的結構 (例如:CNN, RNN, Transformer 等等) 指的 就是不同的候選函式集合
设定标准
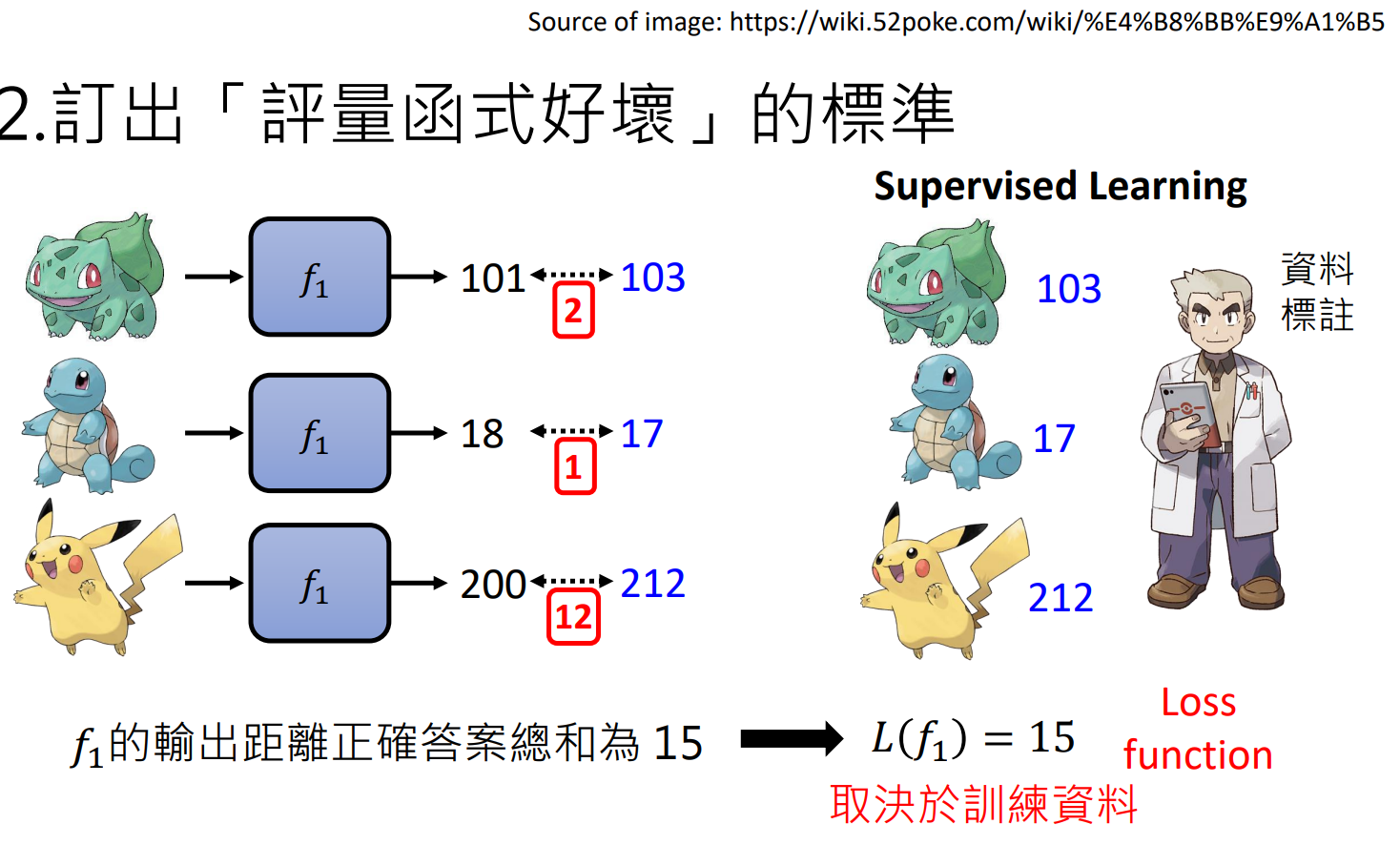
訂出「評量函式好壞」的標準(Loss) 即,要怎么从已确定的函式集合挑出一个最好的。
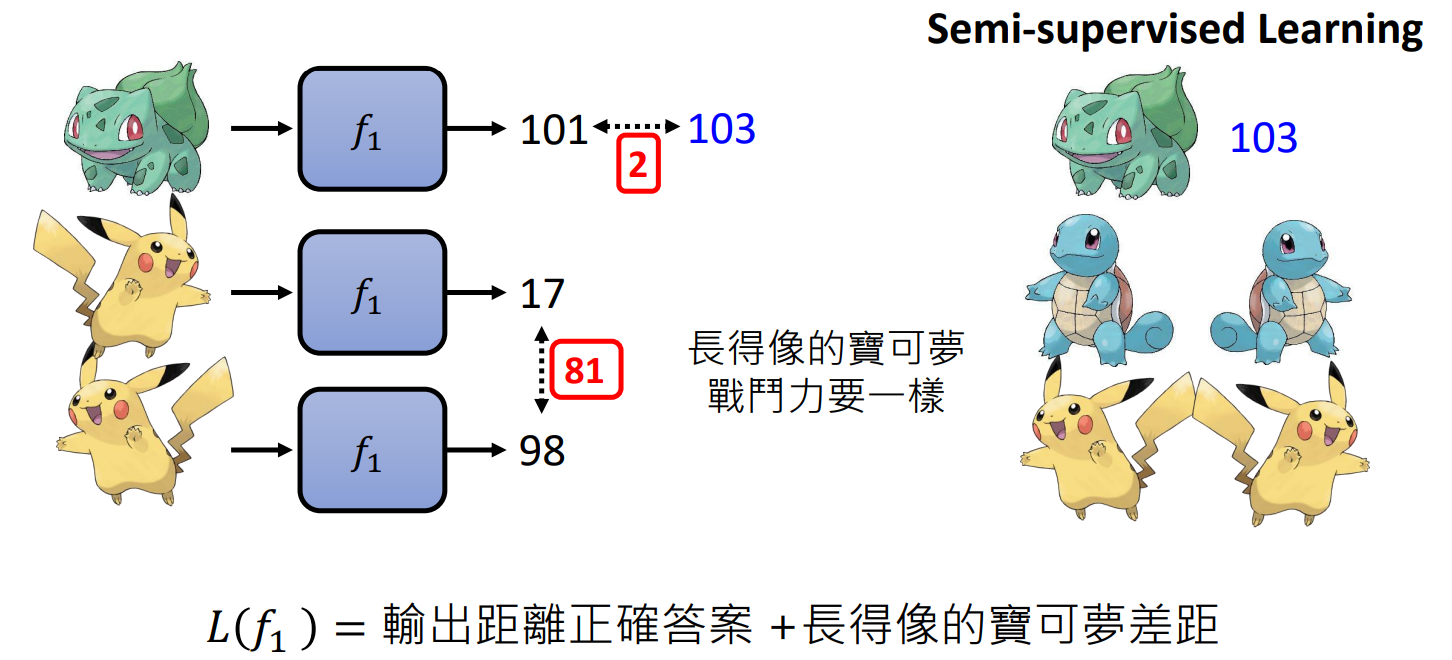
假如训练资料不足:
达成目标
找出最好的函式(即 Loss 最小),这个过程也叫最佳化(Optimization)
正确判断一个机器学习算法属于哪个步骤,不误判其作用。
"RL 要取代 Deep Learning了" 是错误的。 Reinforcement Learning 是评定函式好坏的标准,而 Deep Learning 是定出候选函式的集合,两者不能比较。
三步骤详述
达成目标
最佳化演算法(Optimization Algorithm):
输入:定好的函式的集合$H$,定好的评估函式好坏的标准$L$。
输出:最好的函式 $f∗$,使 $L$ 越小越好
比较好的最佳化演算法可以做到:同样的 $H$ 和 $L$,能更快得出结果,或者得到更低的 $L(f∗)$ (注意,不一定能成功得到最小的 $L(f∗)$)
最佳化演算法需要预先设定好 Learning Rate、Batch Size、How to Init,这些叫做超参数(Hyperparameter)。一个好的最佳化演算法应该对超参数不敏感。
设定标准
使用函式有两个阶段:
训练(Training),找函式的过程,需要训练资料和定好标准的Loss Function
测试(Testing),用上述找出的函式,用不同于训练资料的测试资料,作为输入,期待跑出的输出是正确的。但实际上,训练阶段 $L(f)$ 小,测试阶段不一定好。(需要在 Loss 上做额外考量,如 Regularization)
假如需要定一个跑步标准,采用的方法是让每个学校选出一个学生的跑步成绩,然后取平均值作为所有学生的跑步标准。倘若每个学校所选的是该学校跑步最好学生的成绩,会导致定出来的标准实际上是过高的。
设定范围
为什么要设定候选函式的范围呢?为什么不直接用全天下所有的函式呢?
有些函式 $L(f)$ 小,但测试不好(比如硬记答案,不举一反三),而我们实际需要的是 $L(f)$小且测试好的函式。因此,需要先圈定一个范围,直接将这些不好的函式排除掉。
圈定一个合适的范围并不容易
圈得太大,会将不好的函式也圈进来
圈得太小,可能没圈进一个好的函式 (大海捞针,针还不在海里,怎么捞都捞不到)
训练资料少,设定的范围要小一些
训练资料多,设定的范围可以大一些